RAPTOR:索引树状 RAG,使用树结构来捕捉文本的高级和低级细节
- 提出背景
- 使用树结构来捕捉文本的高级和低级细节
- 递归摘要
- RAPTOR = 递归树结构的构建 + 树遍历或压缩树检索 + 语义关联性检索
- 对比 RAG、知识图谱
- 树遍历检索和压缩树检索
提出背景
论文:https://arxiv.org/pdf/2401.18059
代码:https://github.com/parthsarthi03/raptor
RAPTOR 通过递归地嵌入、聚类和总结文本片段来构建一个具有不同摘要级别的树形结构。
在推理时,RAPTOR模型从这个树中检索信息,将不同摘要级别的长篇文档信息整合在一起。
实验的结果表明,使用递归摘要的检索比传统的检索增强语言模型在多个任务上都取得了显著的改进。
在涉及复杂的多步推理的问答任务中,我们展示了最先进的结果;例如,通过将RAPTOR检索与GPT-4的使用结合起来,可以在QuALITY基准测试中将最佳性能提高20%的绝对准确率。
想象一下你有一个巨大的图书馆,里面装满了有关糖尿病的所有资料和研究。
如果你是图书馆管理员,需要帮助一个研究人员快速找到他们需要的特定信息,你会怎么做?
- 你可能会首先按主题将图书和文献分类,比如治疗方法、饮食建议、药物研究等。
- 然后,在每个主题内部,你可能会继续将资料细分,比如将饮食建议分为针对不同类型糖尿病的饮食策略。
- 当研究人员提出具体问题时,你不仅可以直接指导他们到相关主题的区域,还能进一步引导他们到更细化的资料部分,比如针对他们问题的特定饮食策略文献。
RAPTOR的设计思路类似于这样的图书馆系统。
它不是简单地把所有信息堆放在一起,而是创建了一个结构化的索引树,帮助模型理解和检索具有层次结构的大量文本信息。
通过这样的结构,我们就像是先从图书馆的大厅开始,那里有指向不同主题区域的指示标志(这相当于RAPTOR树的顶层节点),然后我们根据访问者的具体问题,引导他们深入到更具体的书架和书籍(这对应于树的下层节点),直到找到最相关的资料。
正如在一个好的图书馆中,系统的分类和标签帮助你快速找到你需要的书一样,RAPTOR通过其递归摘要和聚类方法,帮助语言模型快速找到并理解长文本中最相关的信息。
使用树结构来捕捉文本的高级和低级细节
“高级”和“低级”细节指的是文本的不同抽象层次。在RAPTOR的上下文中:
-
高级细节:指的是文本的宏观概念和主题,比如在糖尿病领域,这可能是对整个疾病管理策略的总结,治疗原则,或者对疾病概念的宽泛讨论。
-
低级细节:指的是具体事实和数据,例如特定药物的剂量,糖尿病患者的饮食建议的具体内容,或者某项具体研究的实验结果。
递归摘要
递归摘要作为上下文摘要技术:递归摘要提供了文档的简明视图,使人们能够更专注地参与内容。
尽管递归摘要模型对于捕捉更广泛的主题很有效,但可能会忽略细节。
LlamaIndex通过类似的方式摘要相邻的文本块,但也保留了中间节点,因此保留了不同级别的细节,保持了细粒度的细节。
然而,这两种方法由于依赖邻接来对节点进行分组或摘要,可能仍然会忽略文本内的远程依赖关系,而RAPTOR可以找到并组织这些依赖关系。
- llamaindex 分成检索的方法:https://docs.llamaindex.ai/en/stable/examples/query_engine/multi_doc_auto_retrieval/multi_doc_auto_retrieval/
结合递归摘要 + llamaindex 分成检索 + RAPTOR,就像是首先从书籍的目录(高级摘要)开始阅读,你可以得到每个章节的主要话题,然后你再阅读具体章节的小结(中级摘要),最终深入到章节的具体段落(低级细节)。
RAPTOR就是在模拟这个过程,创建一个包含不同信息层次的结构化树。它先从文本的宽泛主题开始,然后递归地深入到更具体的信息点。
使用糖尿病作为例子:
- 假设你需要理解糖尿病的饮食管理。
- 高级摘要可能是关于为什么饮食管理对控制糖尿病至关重要的一般性描述。
- 中级摘要可能会涵盖具体的饮食原则,如低糖、高纤维饮食的好处。
- 低级细节则会提供具体食物列表,例如可以吃的水果和应避免的食物,甚至可能包括具体的食谱和每日饮食计划。
RAPTOR能够整合这些不同层次的信息,帮助用户根据他们的查询深入到合适的信息深度,无论是需要宏观理解还是具体细节。

这张图展示了RAPTOR树构建过程的概览。
它从下至上递归地将文本块聚类,并生成这些聚类的文本摘要,构建出一个树状结构。
具体来说,图分为三部分:
-
RAPTOR树(左侧):显示了一个由底部的叶子层构建到顶部的根层的树。
在叶子层,我们可以看到数字标记的文本块(1至5),它们通过聚类和摘要形成了上一层的节点(6至10)。
-
构建树层的过程(中间):这部分详细展示了如何形成树的一层。
首先,通过聚类将文本块分组(例如,1和4聚类成一个组,2和3聚类成另一个组),然后使用大型语言模型(LLM)对这些聚类进行摘要,形成上一层的节点(例如,节点6是块1和4的摘要)。
-
节点内容(右侧):详细描述了一个节点内的信息,包括节点索引(例如#8),子节点的索引(此例中为2和3),节点文本(即节点2和3的摘要),以及文本嵌入的向量表示。
整个图表强调RAPTOR在构建树形索引时不仅捕捉到了文本的详细内容,而且通过摘要也捕捉到了更高层次的概念。
聚类在一起的节点被视为兄弟节点;父节点包含了该聚类的文本摘要。
这种方法使得检索不仅能考虑到文本的具体信息,还能从更宏观的层面理解信息,有助于在面对需要广泛知识和理解的任务时提供更准确的回答。
RAPTOR = 递归树结构的构建 + 树遍历或压缩树检索 + 语义关联性检索
-
构建RAPTOR树的方法:使用分层递归结构,平衡宏观主题理解和微观细节,并允许基于语义相似性而非文本顺序来分组节点。
- 之所以使用构建树的方法,是因为长文本通常呈现子主题和层次结构,RAPTOR通过这种结构解决阅读中的语义深度和联系问题。
-
文本块的聚类和摘要:运用聚类算法组织文本片段,然后用语言模型对聚类的文本进行摘要。
- 之所以使用聚类和摘要,是为了抓住相关内容并提升后续检索过程的效率。
-
GMM聚类算法:使用高斯混合模型来软聚类,允许节点属于多个类群。
- 之所以使用GMM,是因为文本片段通常包含与不同主题相关的信息,适应于它们被包含在多个摘要中。
-
模型驱动的摘要:将每个聚类的节点传送给语言模型进行摘要。
- 之所以使用模型驱动摘要,是为了将大量文本转化为简洁、连贯的摘要。
-
查询机制:引入树遍历和压缩树两种不同的查询策略。
- 之所以使用这两种查询机制,是为了提供检索多层RAPTOR树以检索相关信息的独特方式。
具体子解法:
-
树遍历查询策略:逐层遍历树,修剪并选择每层最相关的节点。
- 之所以使用树遍历策略,是因为它允许从树的顶层开始,逐渐聚焦于更细致的信息,从而控制检索信息的具体性和广度。
-
压缩树查询策略:将所有节点同时考虑在内,而不是逐层进行,简化搜索过程。
- 之所以使用压缩树策略,是因为它通过同时搜索所有节点,提供了比树遍历更大的灵活性,能够检索出对于给定问题正确细粒度级别的信息。
举个例子,糖尿病。
-
构建RAPTOR树针对糖尿病文献:构建一棵以糖尿病相关研究文献为节点的RAPTOR树,其中包含不同研究的具体细节以及更广泛的糖尿病主题。
- 之所以使用这种方法,是因为糖尿病领域的文献包含了从病理生理学到治疗方法的广泛信息,这种结构有助于综合和整理这些信息。
-
文献聚类和摘要:使用聚类算法将关于糖尿病不同主题(如胰岛素抵抗、饮食治疗、并发症管理等)的研究文献分组,并对每个聚类进行摘要。
- 之所以使用聚类和摘要,是为了将分散的研究成果集中起来,形成对特定主题的综合性描述,便于检索和引用。
-
GMM聚类算法:对糖尿病文献采用GMM聚类,根据内容相似度而非出版顺序组织文献。
- 之所以使用GMM聚类算法,是因为糖尿病研究的各个方面往往相互关联,同一篇文献可能对多个子主题都有贡献。
-
模型驱动的文献摘要:利用语言模型对每个聚类的文献进行摘要,生成容易理解和检索的糖尿病信息。
- 之所以使用模型驱动摘要,是为了将复杂的研究报告转换为易于医生和患者理解的信息。
-
糖尿病信息查询机制:使用树遍历和压缩树查询,检索与糖尿病相关的问题的答案。
- 之所以使用这两种查询机制,是为了提供两种不同的信息检索方式,增加检索的灵活性和准确性。
假设医生想了解糖尿病患者如何调整饮食来控制血糖:
- 使用树遍历查询:首先在RAPTOR树的顶层查找涉及“糖尿病饮食管理”的大类节点,然后逐渐进入子节点,找到具体关于“饮食控制血糖”的研究细节。
- 使用压缩树查询:在RAPTOR树的所有层次中搜索与“饮食控制血糖”直接相关的文献,不受层次顺序限制,可能更直接地找到最具相关性的研究报告和数据。
对比 RAG、知识图谱
在处理糖尿病相关的复杂问题推理时:
-
RAPTOR:通过递归摘要的方式构建一个多层次的信息树,能够从大量的糖尿病文献中有效地检索出相关信息,便于解答涉及多个文献和细节的复杂问题。
-
传统RAG:可能会直接检索出与糖尿病相关的文本块,但在没有树状结构的情况下,可能难以把握文献之间的层次关系和全局概念,对于需要跨文档理解的问题,可能效率较低。
-
知识图谱:可以精确地找到糖尿病相关的实体(如药物、症状、治疗方法)及其关系,适用于需要准确关系和实体信息的查询,但可能不擅长处理需要广泛文本理解的问题。
总结:RAPTOR在处理需要综合多个信息源的复杂推理时表现更佳,传统RAG适合直接的、范围更狭窄的查询,而知识图谱适用于基于精确实体和关系的信息检索。
树遍历检索和压缩树检索
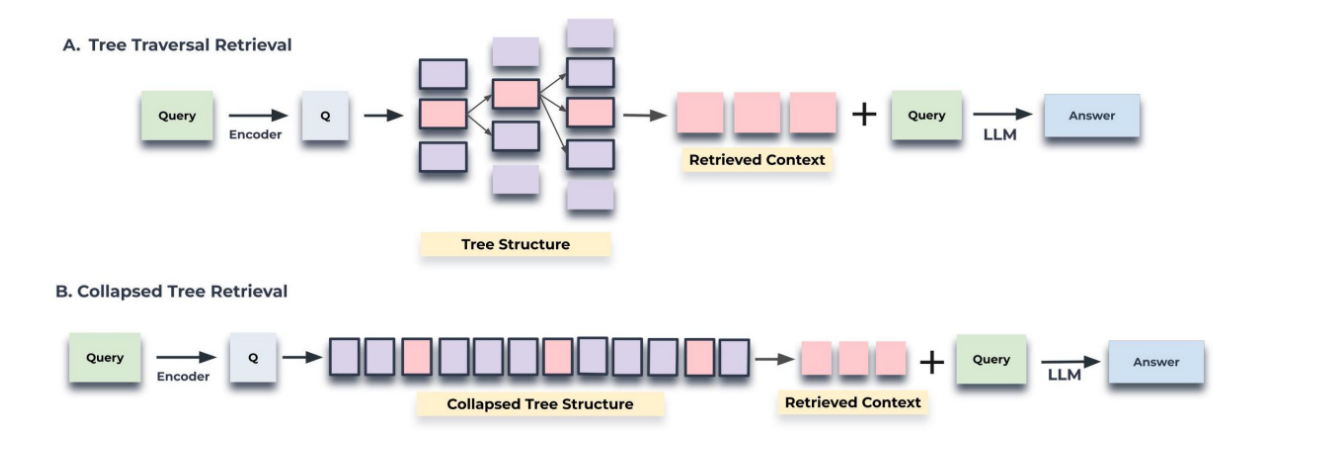
这幅图展示了两种检索机制:树遍历检索和压缩树检索。
A. 树遍历检索:
- 查询通过编码器转换为查询向量(Q)。
- 树遍历从根节点开始,基于查询向量与节点的余弦相似度,选择最相关的节点(top-k)。
- 在树的每个层级重复这一过程,从中选择子节点。
- 所有选择的节点形成检索到的上下文。
- 最后,这个上下文与查询一起送入大型语言模型(LLM),以生成答案。
B. 压缩树检索:
- 查询同样通过编码器转换为查询向量。
- 压缩树将整个树结构压缩为单层,基于查询向量与节点的余弦相似度,检索节点。
- 继续检索节点直到达到预设的令牌(tokens)阈值。
- 选择的节点同样形成检索到的上下文。
- 这个上下文再与查询一起送入LLM,以生成答案。
在两种检索机制的图示中,都高亮显示了根据余弦相似度进行搜索的节点。
这幅图的目的是为了解释RAPTOR检索系统如何通过不同的方法从结构化的文本数据中检索出对于给定查询最相关的信息。
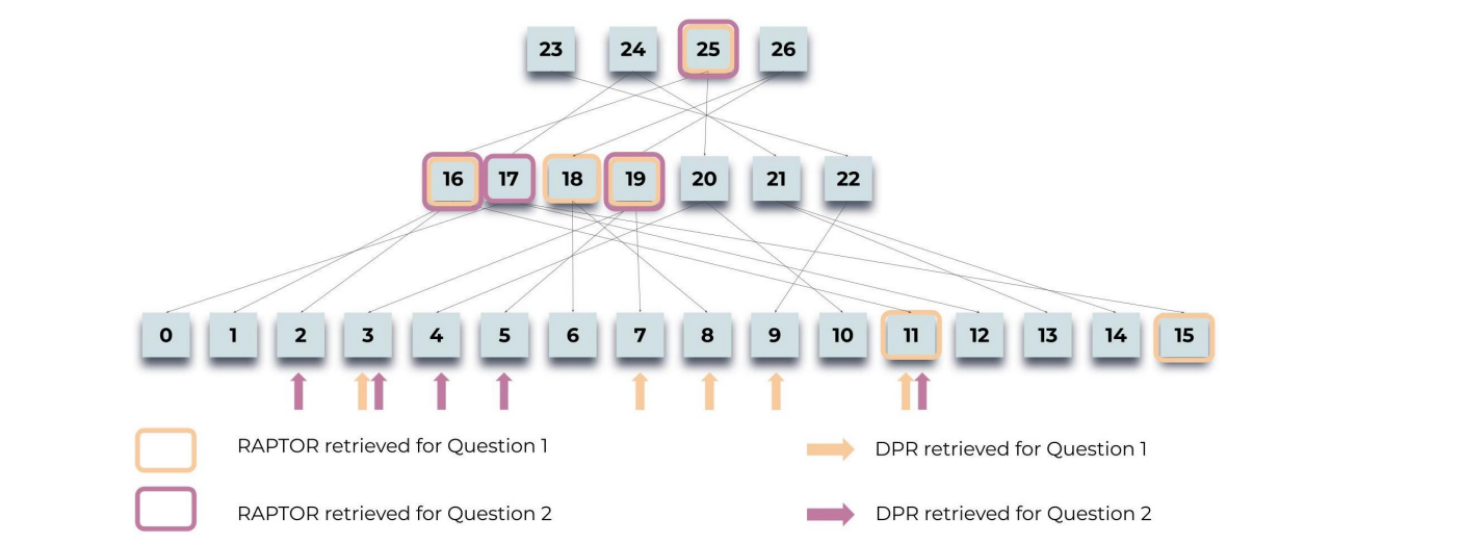
这幅图解释了RAPTOR如何为两个不同的问题从一个文本树中检索信息。
问题是关于《灰姑娘》故事的:“故事的中心主题是什么?”以及“灰姑娘是如何获得幸福结局的?”。
图中突出显示了RAPTOR为回答这些问题选择的节点,同时也展示了传统的Dense Passage Retrieval (DPR)为同一问题检索的文本块。
- 对于第一个问题,RAPTOR选择了更高层的节点(如16, 17, 18, 19),这些节点可能包含故事的摘要或中心主题。
- 对于第二个问题,RAPTOR选择了一些较低层的节点(如2, 3, 4),这些节点可能包含故事的具体部分,例如灰姑娘如何找到她的幸福结局。
箭头指向DPR为每个问题检索的节点,这些节点要么直接来自于原始文本,要么来自更高层的摘要。
图中的颜色编码表明了不同检索方法选择的节点,以及它们在树中的位置。
通过这种比较,图意在展示RAPTOR在检索文本信息时的层次性和上下文覆盖范围,以及与DPR相比的优势。
如果我们将这种检索方式应用于糖尿病相关的信息检索,可能会出现如下情况:
-
假设有两个问题:“糖尿病的主要管理原则是什么?”和“患者如何通过饮食控制糖尿病?”
-
对于第一个问题,关于“糖尿病的主要管理原则”,RAPTOR可能会选择高层的节点,这些节点可能是对糖尿病管理策略、治疗原则的综述,就像节点16, 17, 18, 19可能是关于《灰姑娘》故事主题的摘要一样。
-
对于第二个问题,关于“饮食如何控制糖尿病”,RAPTOR可能会选择较低层的节点,例如包含具体饮食建议、食物指南或者研究结果的文本块,类似于节点2, 3, 4可能含有灰姑娘故事中具体情节的部分。
与此同时,传统的DPR方法可能仅检索几个与问题最直接相关的文本块,而不考虑这些文本块在整个文档中的层次位置或它们如何彼此关联。
通过这种方法,RAPTOR能够为不同类型的问题提供更全面的答案,不仅包括一般性原则也包括具体操作,这在处理复杂和多层面的问题如糖尿病管理时非常有用。

![[SpringBoot] JWT令牌——登录校验](https://img-blog.csdnimg.cn/direct/f3e15d2da1614faab321b80c96743d14.png)